





企業や組織では、日々膨大なドキュメントが生成され、それらを効率的に検索して必要な情報に素早くアクセスすることが求められています。そこで、Python の Streamlit、scikit-learn を活用して、ドキュメント検索システムを構築する方法と、その背後にある類似度計算について解説します。この記事では、特に「類似度」の概念に焦点を当て、検索クエリに対してどのようにドキュメントが一致するかを詳しく説明します。
ドキュメント検索システムの概要
今回のシステムは、指定したディレクトリ内のPDF、Word、Excel、PowerPoint などのドキュメントを再帰的に読み込み、ユーザーのクエリに基づいて関連性の高いドキュメントを検索します。検索の精度を向上させるために、TF-IDF(Term Frequency-Inverse Document Frequency) と コサイン類似度 を使用しています。
システムの仕組み
- ドキュメントの読み込み:
- 指定したディレクトリ内にある
.pdf、.docx、.xlsx、.pptxファイルからテキストを抽出します。
- 指定したディレクトリ内にある
- クエリの入力:
- ユーザーは検索したい単語やフレーズをクエリとして入力します。
- TF-IDF によるベクトル化:
- ドキュメントとクエリを数値データ(ベクトル)に変換し、それぞれの単語の重みを計算します。
- コサイン類似度による検索:
- クエリと各ドキュメントのベクトル間の類似度を計算し、最も関連性の高いドキュメントを返します。
コサイン類似度の仕組み
コサイン類似度とは?
コサイン類似度(Cosine Similarity)は、2つのベクトル間の角度のコサイン値を使って、データの類似度を測定する方法です。この手法では、ベクトル間の角度が小さいほど類似度が高く、角度が90度に近いほど類似度が低いとみなされます。
- 類似度の範囲:0 から 1 の間で値を取ります。
- 1.0 に近い:クエリとドキュメントが非常に似ている。
- 0.0 に近い:クエリとドキュメントが全く異なる。
コサイン類似度の計算方法
コサイン類似度は、以下の数式で計算されます
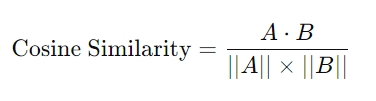
- A と B はそれぞれクエリとドキュメントのベクトル。
- A ⋅ B は 2つのベクトルの内積。
- ||A|| と ||B|| はベクトルのノルム(大きさ)。
類似度の例
例えば、以下の2つの文章があるとします:
- クエリ:
"Python" - ドキュメント A:
"Python programming language" - ドキュメント B:
"Java programming language"
この場合、クエリ "Python" とドキュメント A との類似度は 1.0 に近くなり、ドキュメント B との類似度は 0.0 になります。
単語検索と類似度の関係
単語検索における類似度
検索クエリに含まれる単語がドキュメント内に完全一致しても、追加の単語(形容詞や副詞など)が多い場合、類似度は下がります。これは、TF-IDF によってベクトル化されたドキュメントが、クエリにない単語によって異なる方向に広がるためです。
具体例
- クエリ:
"Python" - ドキュメント A:
"Python is a programming language." - ドキュメント B:
"Python is a versatile programming language used in various fields."
この場合、ドキュメント B にはクエリにない形容詞や追加の単語が含まれているため、類似度はドキュメント A よりも低くなります。
どうして類似度が下がるのか?
- TF-IDF は単語の頻度と逆文書頻度を考慮して各単語に重みを付けます。
- クエリにない単語が多く含まれるドキュメントは、ベクトルの方向が異なり、クエリとのコサイン類似度が低下します。
- そのため、クエリとドキュメントの単語が完全に一致しても、他の単語の影響で類似度が下がるのです。
検索システムの改善方法
より正確な検索結果を得るためには、以下の手法を導入することが一般的です。
1. ストップワードの除去
検索時に “the”, “is”, “a” などの一般的な単語(ストップワード)を無視することで、クエリに含まれる意味のある単語に焦点を当てます。
2. ステミングとレンマ化
単語の変形(例: "programming" → "program")を統一することで、より正確な検索結果を得ることができます。
3. 意味ベースの検索(BERT などの NLP モデル)
TF-IDF に代わって BERT や Word2Vec などの高度な自然言語処理モデルを使用することで、文脈に基づいた検索が可能です。
まとめ
今回の記事では、Python と Streamlit を活用したドキュメント検索システムの仕組みと、TF-IDF およびコサイン類似度を用いた検索アルゴリズムについて解説しました。
キーポイント
- コサイン類似度は、ドキュメントの長さに依存せず、クエリとドキュメントの内容の一致度を測定します。
- クエリに含まれない単語が多いドキュメントは、類似度が低下するため、ストップワードの除去やステミングを利用して精度を向上させることができます。
- より高度な検索を実現するためには、BERT や Word2Vec のような NLP モデルの導入が有効です。
このシステムを導入することで、企業内の情報検索やドキュメント管理が効率化され、業務の生産性向上につながるでしょう。


















